bool PipelineImpl::OptimizeGraph(Linkage* linkage) { PipelineData* data = this->data_;
data->BeginPhaseKind("V8.TFLowering");
// Type the graph and keep the Typer running such that new nodes get // automatically typed when they are created. Run<TyperPhase>(data->CreateTyper()); //typer阶段 RunPrintAndVerify(TyperPhase::phase_name()); Run<TypedLoweringPhase>(); //typerlowering RunPrintAndVerify(TypedLoweringPhase::phase_name());
if (FLAG_turbo_load_elimination) { Run<LoadEliminationPhase>(); //LoadElimination RunPrintAndVerify(LoadEliminationPhase::phase_name()); } data->DeleteTyper();
if (FLAG_turbo_escape) { Run<EscapeAnalysisPhase>(); //EscapeAnalysis if (data->compilation_failed()) { info()->AbortOptimization( BailoutReason::kCyclicObjectStateDetectedInEscapeAnalysis); data->EndPhaseKind(); returnfalse; } RunPrintAndVerify(EscapeAnalysisPhase::phase_name()); }
if (FLAG_assert_types) { Run<TypeAssertionsPhase>(); //TypeAssertions RunPrintAndVerify(TypeAssertionsPhase::phase_name()); }
// Perform simplified lowering. This has to run w/o the Typer decorator, // because we cannot compute meaningful types anyways, and the computed types // might even conflict with the representation/truncation logic. Run<SimplifiedLoweringPhase>(); //SimplifiedLowering RunPrintAndVerify(SimplifiedLoweringPhase::phase_name(), true);
// From now on it is invalid to look at types on the nodes, because the types // on the nodes might not make sense after representation selection due to the // way we handle truncations; if we'd want to look at types afterwards we'd // essentially need to re-type (large portions of) the graph.
// In order to catch bugs related to type access after this point, we now // remove the types from the nodes (currently only in Debug builds). #ifdef DEBUG Run<UntyperPhase>(); RunPrintAndVerify(UntyperPhase::phase_name(), true); #endif //...... }
// Determine the entry point for which this OSR request has been fired and // also disarm all back edges in the calling code to stop new requests. BailoutId ast_id = DetermineEntryAndDisarmOSRForInterpreter(frame); DCHECK(!ast_id.IsNone());
MaybeHandle<Code> maybe_result; if (IsSuitableForOnStackReplacement(isolate, function)) { if (FLAG_trace_osr) { PrintF("[OSR - Compiling: "); function->PrintName(); PrintF(" at AST id %d]\n", ast_id.ToInt()); } maybe_result = Compiler::GetOptimizedCodeForOSR(function, ast_id, frame); //important }
// Make sure we clear the optimization marker on the function so that we // don't try to re-optimize. if (function->HasOptimizationMarker()) { function->ClearOptimizationMarker(); }
if (shared->optimization_disabled() && shared->disable_optimization_reason() == BailoutReason::kNeverOptimize) { return MaybeHandle<Code>(); }
if (isolate->debug()->needs_check_on_function_call()) { // Do not optimize when debugger needs to hook into every call. return MaybeHandle<Code>(); }
// If code was pending optimization for testing, delete remove the entry // from the table that was preventing the bytecode from being flushed if (V8_UNLIKELY(FLAG_testing_d8_test_runner)) { PendingOptimizationTable::FunctionWasOptimized(isolate, function); }
Handle<Code> cached_code; if (GetCodeFromOptimizedCodeCache(function, osr_offset) .ToHandle(&cached_code)) { if (FLAG_trace_opt) { PrintF("[found optimized code for "); function->ShortPrint(); if (!osr_offset.IsNone()) { PrintF(" at OSR AST id %d", osr_offset.ToInt()); } PrintF("]\n"); } return cached_code; }
// Reset profiler ticks, function is no longer considered hot. DCHECK(shared->is_compiled()); function->feedback_vector().set_profiler_ticks(0);
DCHECK(!isolate->has_pending_exception()); PostponeInterruptsScope postpone(isolate); bool has_script = shared->script().IsScript(); // BUG(5946): This DCHECK is necessary to make certain that we won't // tolerate the lack of a script without bytecode. DCHECK_IMPLIES(!has_script, shared->HasBytecodeArray()); std::unique_ptr<OptimizedCompilationJob> job( compiler::Pipeline::NewCompilationJob(isolate, function, has_script)); OptimizedCompilationInfo* compilation_info = job->compilation_info();
// Do not use TurboFan if we need to be able to set break points. if (compilation_info->shared_info()->HasBreakInfo()) { compilation_info->AbortOptimization(BailoutReason::kFunctionBeingDebugged); return MaybeHandle<Code>(); }
// Do not use TurboFan if optimization is disabled or function doesn't pass // turbo_filter. if (!FLAG_opt || !shared->PassesFilter(FLAG_turbo_filter)) { compilation_info->AbortOptimization(BailoutReason::kOptimizationDisabled); return MaybeHandle<Code>(); }
// In case of concurrent recompilation, all handles below this point will be // allocated in a deferred handle scope that is detached and handed off to // the background thread when we return. base::Optional<CompilationHandleScope> compilation; if (mode == ConcurrencyMode::kConcurrent) { compilation.emplace(isolate, compilation_info); }
// All handles below will be canonicalized. CanonicalHandleScope canonical(isolate);
// Reopen handles in the new CompilationHandleScope. compilation_info->ReopenHandlesInNewHandleScope(isolate);
if (mode == ConcurrencyMode::kConcurrent) { if (GetOptimizedCodeLater(job.get(), isolate)) { job.release(); // The background recompile job owns this now.
// Set the optimization marker and return a code object which checks it. function->SetOptimizationMarker(OptimizationMarker::kInOptimizationQueue); DCHECK(function->IsInterpreted() || (!function->is_compiled() && function->shared().IsInterpreted())); DCHECK(function->shared().HasBytecodeArray()); return BUILTIN_CODE(isolate, InterpreterEntryTrampoline); } } else { if (GetOptimizedCodeNow(job.get(), isolate)) //important return compilation_info->code(); }
if (!FLAG_always_opt) { compilation_info()->MarkAsBailoutOnUninitialized(); } if (FLAG_turbo_loop_peeling) { compilation_info()->MarkAsLoopPeelingEnabled(); } if (FLAG_turbo_inlining) { compilation_info()->MarkAsInliningEnabled(); } if (FLAG_inline_accessors) { compilation_info()->MarkAsAccessorInliningEnabled(); }
// This is the bottleneck for computing and setting poisoning level in the // optimizing compiler. PoisoningMitigationLevel load_poisoning = PoisoningMitigationLevel::kDontPoison; if (FLAG_untrusted_code_mitigations) { // For full mitigations, this can be changed to // PoisoningMitigationLevel::kPoisonAll. load_poisoning = PoisoningMitigationLevel::kPoisonCriticalOnly; } compilation_info()->SetPoisoningMitigationLevel(load_poisoning);
if (FLAG_turbo_allocation_folding) { compilation_info()->MarkAsAllocationFoldingEnabled(); }
// Determine whether to specialize the code for the function's context. // We can't do this in the case of OSR, because we want to cache the // generated code on the native context keyed on SharedFunctionInfo. // TODO(mythria): Check if it is better to key the OSR cache on JSFunction and // allow context specialization for OSR code. if (compilation_info()->closure()->raw_feedback_cell().map() == ReadOnlyRoots(isolate).one_closure_cell_map() && !compilation_info()->is_osr()) { compilation_info()->MarkAsFunctionContextSpecializing(); data_.ChooseSpecializationContext(); }
if (compilation_info()->is_source_positions_enabled()) { SharedFunctionInfo::EnsureSourcePositionsAvailable( isolate, compilation_info()->shared_info()); }
linkage_ = new (compilation_info()->zone()) Linkage( Linkage::ComputeIncoming(compilation_info()->zone(), compilation_info()));
if (compilation_info()->is_osr()) data_.InitializeOsrHelper();
// Make sure that we have generated the deopt entries code. This is in order // to avoid triggering the generation of deopt entries later during code // assembly. Deoptimizer::EnsureCodeForDeoptimizationEntries(isolate);
pipeline_.Serialize();
if (!FLAG_concurrent_inlining) { if (!pipeline_.CreateGraph()) { CHECK(!isolate->has_pending_exception()); return AbortOptimization(BailoutReason::kGraphBuildingFailed); } }
// Perform function context specialization and inlining (if enabled). Run<InliningPhase>(); RunPrintAndVerify(InliningPhase::phase_name(), true);
// Remove dead->live edges from the graph. Run<EarlyGraphTrimmingPhase>(); RunPrintAndVerify(EarlyGraphTrimmingPhase::phase_name(), true);
// Determine the Typer operation flags. { SharedFunctionInfoRef shared_info(data->broker(), info()->shared_info()); if (is_sloppy(shared_info.language_mode()) && shared_info.IsUserJavaScript()) { // Sloppy mode functions always have an Object for this. data->AddTyperFlag(Typer::kThisIsReceiver); } if (IsClassConstructor(shared_info.kind())) { // Class constructors cannot be [[Call]]ed. data->AddTyperFlag(Typer::kNewTargetIsReceiver); } }
// Run the type-sensitive lowerings and optimizations on the graph. { if (!FLAG_concurrent_inlining) { Run<HeapBrokerInitializationPhase>(); Run<CopyMetadataForConcurrentCompilePhase>(); data->broker()->StopSerializing(); } }
// Set up the basic structure of the graph. Outputs for {Start} are the formal // parameters (including the receiver) plus new target, number of arguments, // context and closure. int actual_parameter_count = bytecode_array().parameter_count() + 4; //定义参数个数 graph()->SetStart(graph()->NewNode(common()->Start(actual_parameter_count))); //新建一个start //结点并设置Start //common结点统一在common-operator.cc中
// Passing the OptimizedCompilationInfo's shared zone here as // JSNativeContextSpecialization allocates out-of-heap objects // that need to live until code generation.
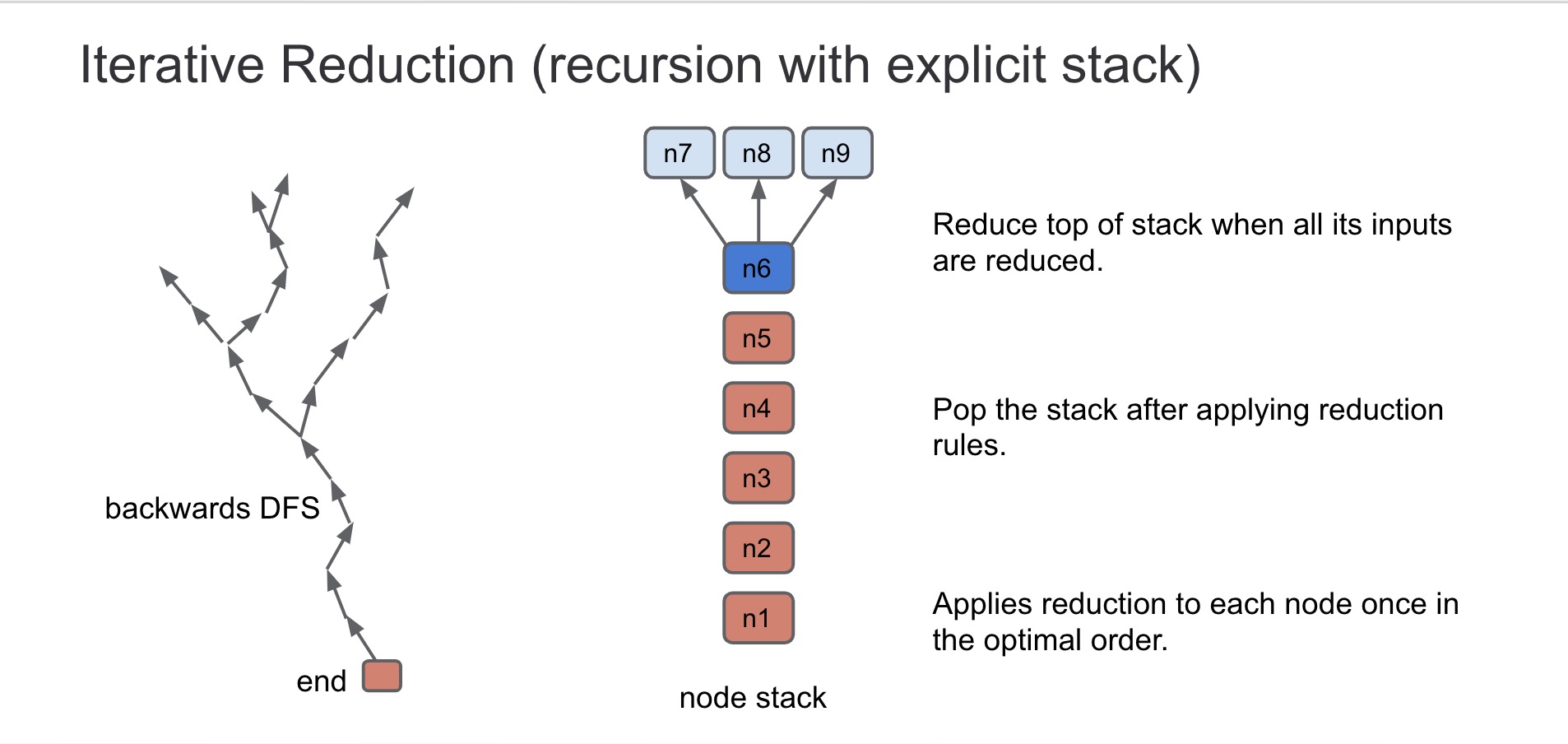
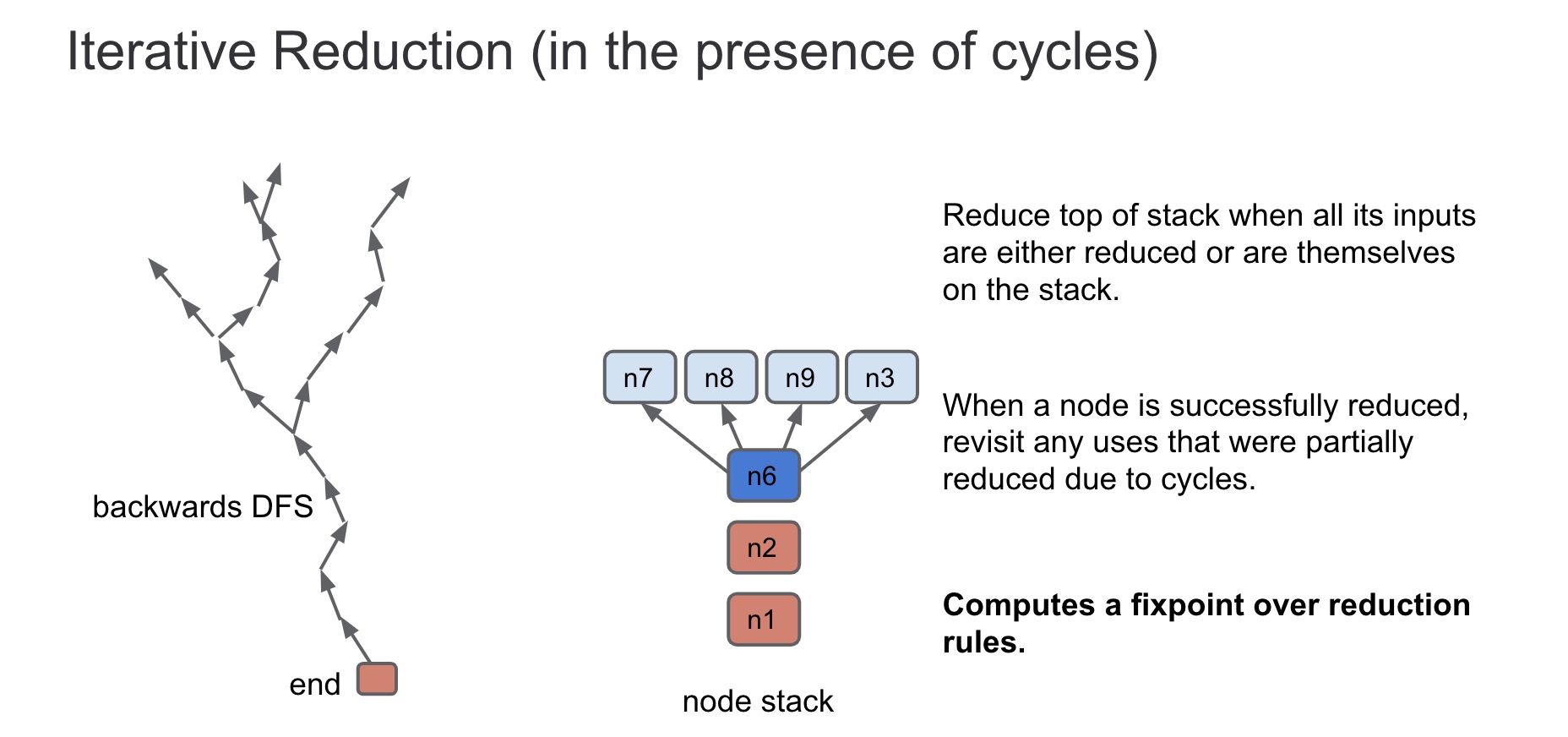
void GraphReducer::ReduceNode(Node* node) { DCHECK(stack_.empty()); DCHECK(revisit_.empty()); Push(node);//将node push 到 stack_中 for (;;) { if (!stack_.empty()) { //stack_不为空 // Process the node on the top of the stack, potentially pushing more or // popping the node off the stack. ReduceTop(); } elseif (!revisit_.empty()) {//revisit_不为空 // If the stack becomes empty, revisit any nodes in the revisit queue. Node* const node = revisit_.front(); revisit_.pop(); if (state_.Get(node) == State::kRevisit) { // state can change while in queue. Push(node); } } else { // Run all finalizers. for (Reducer* const reducer : reducers_) reducer->Finalize();
// Check if we have new nodes to revisit. if (revisit_.empty()) break; } }//for (;;) DCHECK(revisit_.empty()); DCHECK(stack_.empty()); }
// If there was no reduction, pop {node} and continue. // 没有对该节点reduce,则pop if (!reduction.Changed()) return Pop();
// Check if the reduction is an in-place update of the {node}. Node* const replacement = reduction.replacement(); if (replacement == node) { //replacement == node 代表该node被更新 // In-place update of {node}, may need to recurse on an input. Node::Inputs node_inputs = node->inputs(); for (int i = 0; i < node_inputs.count(); ++i) { Node* input = node_inputs[i]; if (input != node && Recurse(input)) { entry.input_index = i + 1; return; } } }
// After reducing the node, pop it off the stack. Pop();
// Check if we have a new replacement. if (replacement != node) { Replace(node, replacement, max_id); } else { // Revisit all uses of the node. // 重新访问该节点的use节点,入栈 for (Node* const user : node->uses()) { // Don't revisit this node if it refers to itself. if (user != node) Revisit(user); } } }
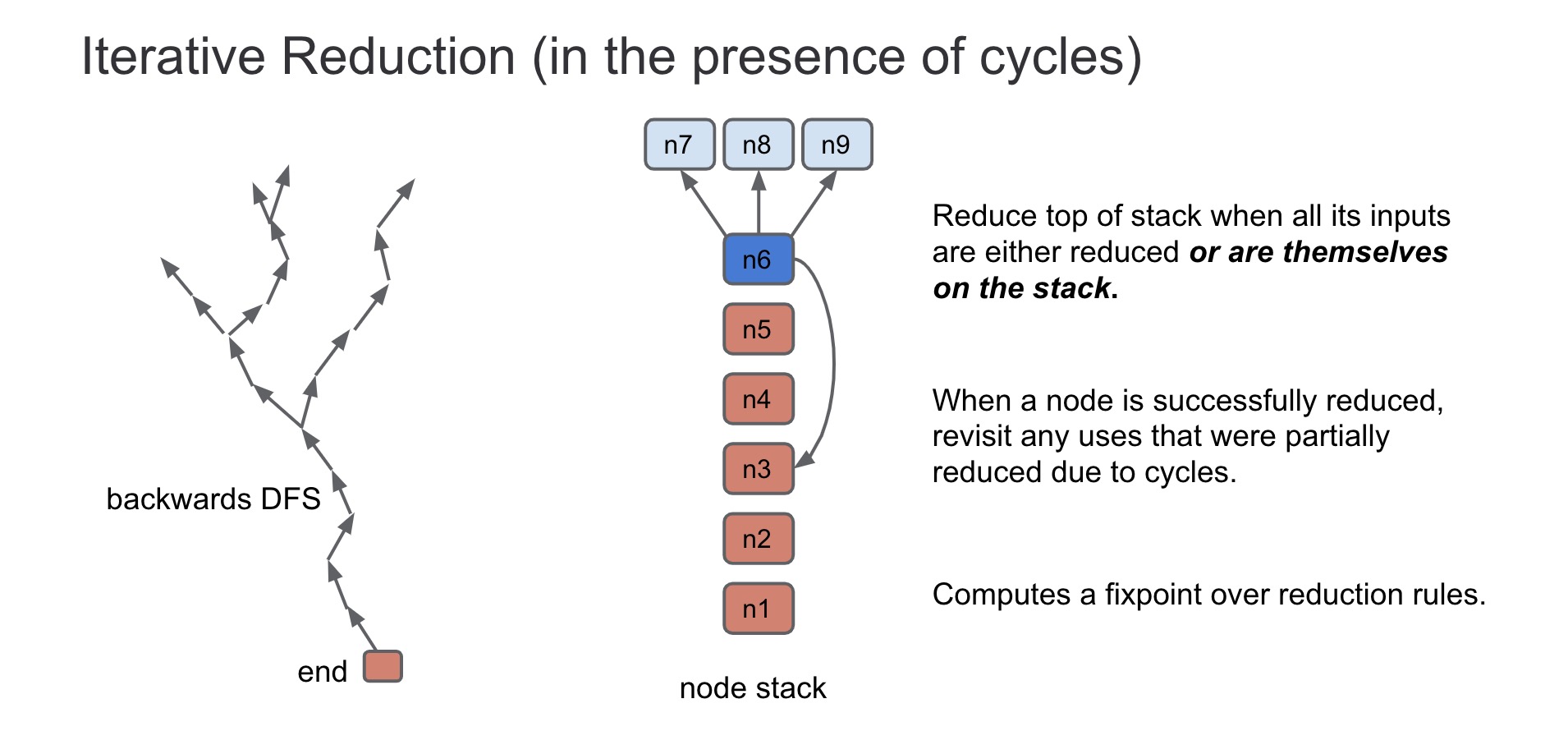
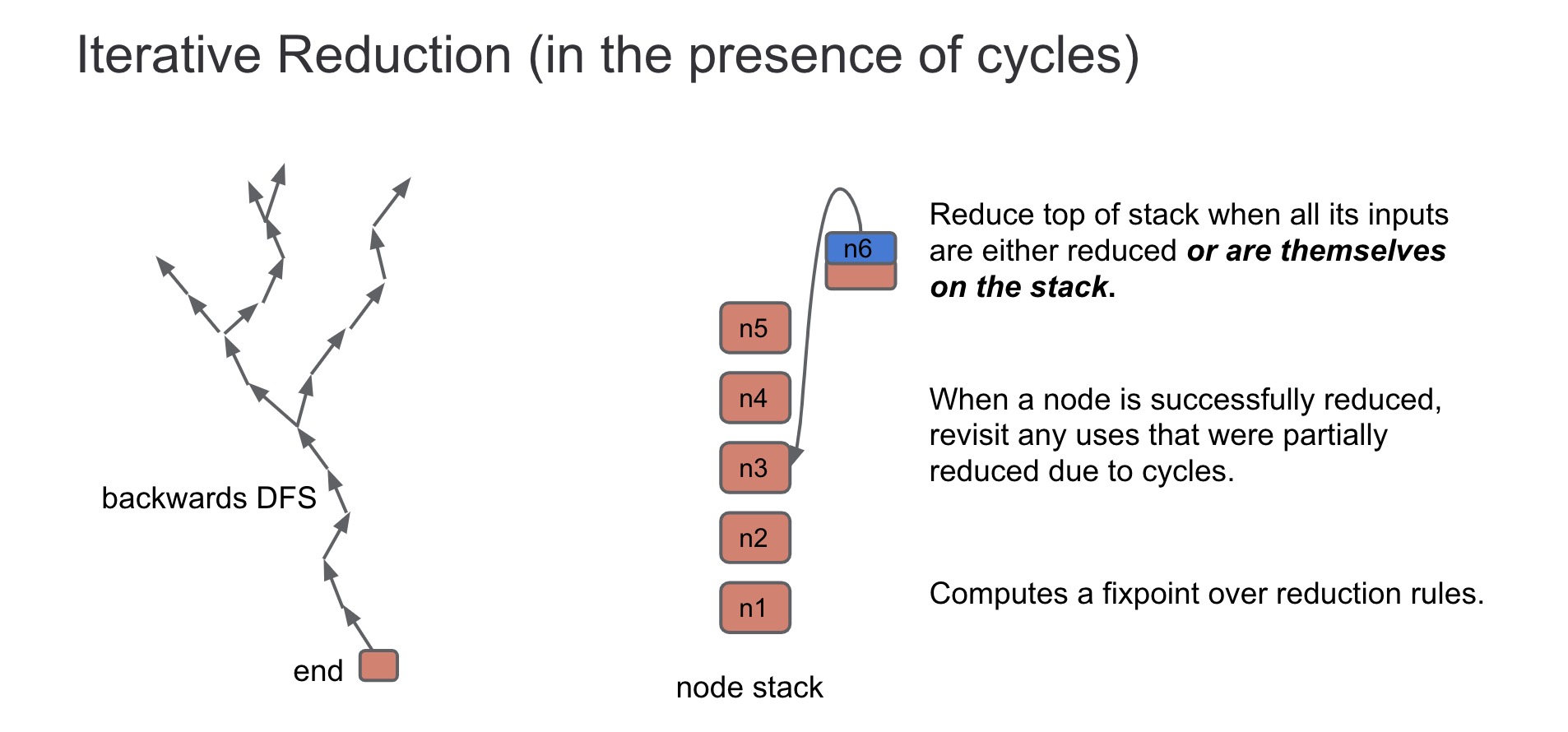
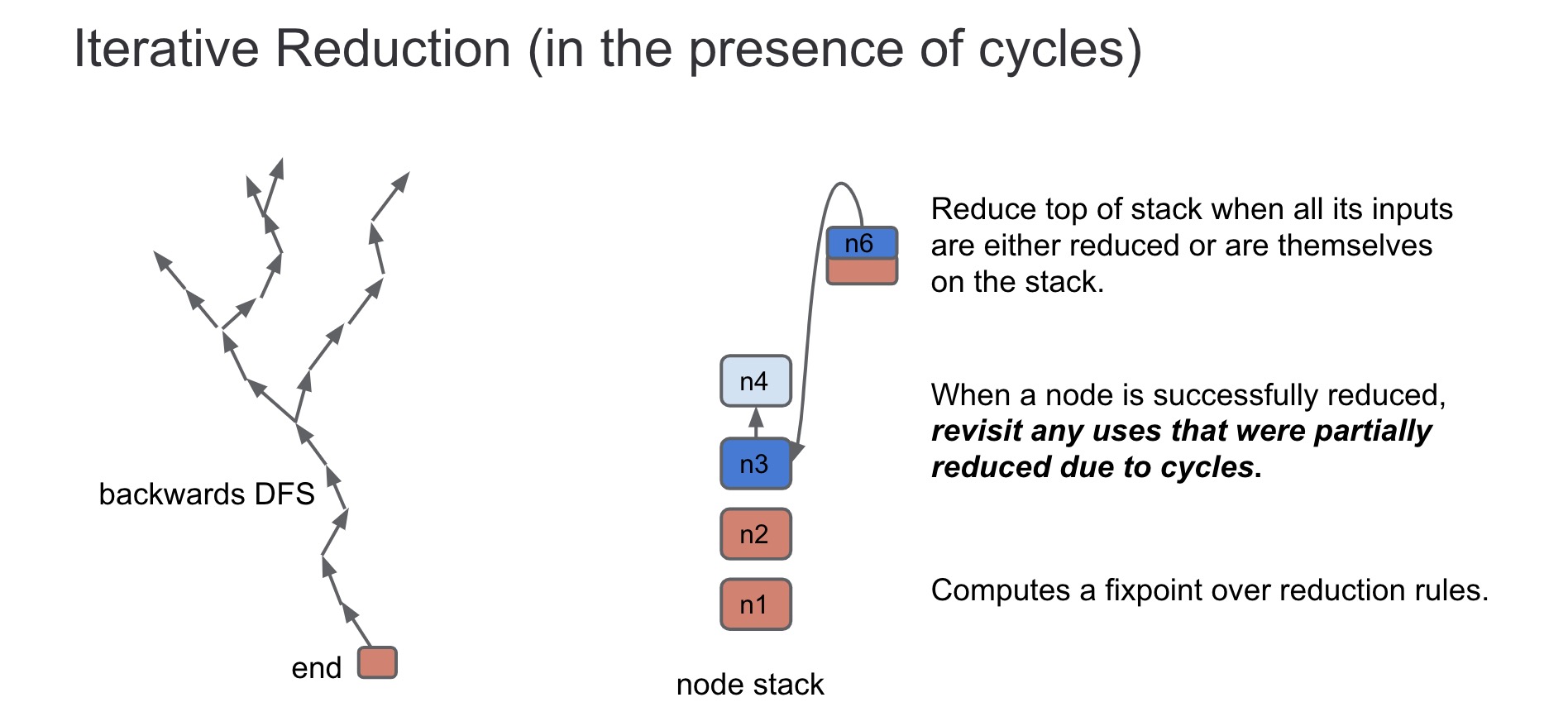
void GraphReducer::ReduceNode(Node* node) { DCHECK(stack_.empty()); DCHECK(revisit_.empty()); Push(node); //压入stack栈中 for (;;) { if (!stack_.empty()) { //如果stack栈中不为空,则进入ReduceTop函数中 // Process the node on the top of the stack, potentially pushing more or // popping the node off the stack. ReduceTop(); } elseif (!revisit_.empty()) { //如果revisit栈中不为空,则pop掉栈顶节点检查是否为kRevisit标记,是则标记为kOnStack然后压入stack栈中 // If the stack becomes empty, revisit any nodes in the revisit queue. Node* const node = revisit_.front(); revisit_.pop(); if (state_.Get(node) == State::kRevisit) { // state can change while in queue. Push(node); } } else { //如果stack、revisit栈都空,则执行所有reduce的析构函数,并检查revisit栈是否为空,是则结束循环 // Run all finalizers. for (Reducer* const reducer : reducers_) reducer->Finalize();
// Check if we have new nodes to revisit. if (revisit_.empty()) break; } } DCHECK(revisit_.empty()); DCHECK(stack_.empty()); }
// Recurse on an input if necessary. //下面两个循环其实可以结合在一起,用的就是把每个input节点都遍历一遍,先遍历input_index后面部分,再遍历前面 //(分开来的话感觉是作用于input_index赋值的?) int start = entry.input_index < node_inputs.count() ? entry.input_index : 0; for (int i = start; i < node_inputs.count(); ++i) { Node* input = node_inputs[i];
//如果该input节点不为该node节点,且>kRevisit标记,return false if (input != node && Recurse(input)) { //input_index加一 entry.input_index = i + 1; return; } } for (int i = 0; i < start; ++i) { Node* input = node_inputs[i]; if (input != node && Recurse(input)) { entry.input_index = i + 1; return; } }
// Remember the max node id before reduction. NodeId const max_id = static_cast<NodeId>(graph()->NodeCount() - 1);
// All inputs should be visited or on stack. Apply reductions to node. Reduction reduction = Reduce(node);
// If there was no reduction, pop {node} and continue. //如果该node在reduce中没有改变,则标记kVisited后pop stack栈 if (!reduction.Changed()) return Pop();
// Check if the reduction is an in-place update of the {node}. Node* const replacement = reduction.replacement(); //如果发生了节点状态更新,则需要重新遍历每个inputs节点查看是否有kRevisited标记并push到stack栈上 if (replacement == node) { // In-place update of {node}, may need to recurse on an input. Node::Inputs node_inputs = node->inputs(); for (int i = 0; i < node_inputs.count(); ++i) { Node* input = node_inputs[i]; if (input != node && Recurse(input)) { entry.input_index = i + 1; return; } } }
// After reducing the node, pop it off the stack. //标记kVisited并pop stack栈 Pop();
// Check if we have a new replacement. //如果该node直接被替换了,则进入Replace if (replacement != node) { Replace(node, replacement, max_id); } else { //否则该node的use节点如果不指向自己且都为kVisited标记,则标记为kRevisit并push到revisit栈中 // Revisit all uses of the node. for (Node* const user : node->uses()) { // Don't revisit this node if it refers to itself. if (user != node) Revisit(user); } } }
Reduction GraphReducer::Reduce(Node* const node) { auto skip = reducers_.end(); for (auto i = reducers_.begin(); i != reducers_.end();) { if (i != skip) { tick_counter_->DoTick(); Reduction reduction = (*i)->Reduce(node); if (!reduction.Changed()) { //如果该node在该reduce下没有任何change,则进行下一个reduce // No change from this reducer. } elseif (reduction.replacement() == node) {
//如果node发生了状态更新(非替换),则重新遍历除该reduce之外的所有reduce //同时skip变成该reduce // {replacement} == {node} represents an in-place reduction. Rerun // all the other reducers for this node, as now there may be more // opportunities for reduction. if (FLAG_trace_turbo_reduction) { StdoutStream{} << "- In-place update of " << *node << " by reducer " << (*i)->reducer_name() << std::endl; } skip = i; i = reducers_.begin(); continue; } else { //如果node被替换了,则直接返回该reduce // {node} was replaced by another node. if (FLAG_trace_turbo_reduction) { StdoutStream{} << "- Replacement of " << *node << " with " << *(reduction.replacement()) << " by reducer " << (*i)->reducer_name() << std::endl; } return reduction; } } ++i; } //如果skip为最后一个reduce则node没有发生过改变 if (skip == reducers_.end()) { // No change from any reducer. return Reducer::NoChange(); } //如果不是则至少发生了一次状态更新(即一个reduce发生作用) // At least one reducer did some in-place reduction. return Reducer::Changed(node); }
// Perform function context specialization and inlining (if enabled). Run<InliningPhase>(); RunPrintAndVerify(InliningPhase::phase_name(), true);
// Remove dead->live edges from the graph. Run<EarlyGraphTrimmingPhase>(); RunPrintAndVerify(EarlyGraphTrimmingPhase::phase_name(), true);
//确定typer阶段的flag标志 // Determine the Typer operation flags. { SharedFunctionInfoRef shared_info(data->broker(), info()->shared_info()); //如果是sloppy模式则添加kThisIsReceiver标识(表示this参数是一个Object) if (is_sloppy(shared_info.language_mode()) && shared_info.IsUserJavaScript()) { // Sloppy mode functions always have an Object for this. data->AddTyperFlag(Typer::kThisIsReceiver); } //(表示参数new.target是一个Object) if (IsClassConstructor(shared_info.kind())) { // Class constructors cannot be [[Call]]ed. data->AddTyperFlag(Typer::kNewTargetIsReceiver); } }
//类型敏感的简化和优化(一般不会执行) // Run the type-sensitive lowerings and optimizations on the graph. { if (!FLAG_concurrent_inlining) { //初始化一些标准对象 Run<HeapBrokerInitializationPhase>(); //调用JSHeapCopyReducer Run<CopyMetadataForConcurrentCompilePhase>(); //标记已序列化过(kSerialized) data->broker()->StopSerializing(); } }
// Make sure we always type True and False. Needed for escape analysis. //节点向量加入True False常数(为逃逸分析阶段做准备) roots.push_back(data->jsgraph()->TrueConstant()); roots.push_back(data->jsgraph()->FalseConstant());
Reduction DeadCodeElimination::Reduce(Node* node) { DisallowHeapAccess no_heap_access; switch (node->opcode()) { case IrOpcode::kEnd: return ReduceEnd(node); case IrOpcode::kLoop: case IrOpcode::kMerge: return ReduceLoopOrMerge(node); case IrOpcode::kLoopExit: return ReduceLoopExit(node); case IrOpcode::kUnreachable: case IrOpcode::kIfException: return ReduceUnreachableOrIfException(node); case IrOpcode::kPhi: return ReducePhi(node); case IrOpcode::kEffectPhi: return ReduceEffectPhi(node); case IrOpcode::kDeoptimize: case IrOpcode::kReturn: case IrOpcode::kTerminate: case IrOpcode::kTailCall: return ReduceDeoptimizeOrReturnOrTerminateOrTailCall(node); case IrOpcode::kThrow: return PropagateDeadControl(node); case IrOpcode::kBranch: case IrOpcode::kSwitch: return ReduceBranchOrSwitch(node); default: return ReduceNode(node); } UNREACHABLE(); }
Reduction DeadCodeElimination::ReduceLoopOrMerge(Node* node) { DCHECK(IrOpcode::IsMergeOpcode(node->opcode())); Node::Inputs inputs = node->inputs(); DCHECK_LE(1, inputs.count()); // Count the number of live inputs to {node} and compact them on the fly, also // compacting the inputs of the associated {Phi} and {EffectPhi} uses at the // same time. We consider {Loop}s dead even if only the first control input // is dead. int live_input_count = 0; //是否为loop节点,且第一个input节点是否为dead节点 //后续跟上面函数一样,紧凑非dead节点 if (node->opcode() != IrOpcode::kLoop || node->InputAt(0)->opcode() != IrOpcode::kDead) { for (int i = 0; i < inputs.count(); ++i) { Node* const input = inputs[i]; // Skip dead inputs. if (input->opcode() == IrOpcode::kDead) continue; // Compact live inputs. if (live_input_count != i) { node->ReplaceInput(live_input_count, input); //还遍历use节点为Phi、EffectPhi的节点,如果是则把use节点的input节点也紧凑一遍 for (Node* const use : node->uses()) { if (NodeProperties::IsPhi(use)) { DCHECK_EQ(inputs.count() + 1, use->InputCount()); use->ReplaceInput(live_input_count, use->InputAt(i)); } } } ++live_input_count; } } if (live_input_count == 0) { return Replace(dead()); } elseif (live_input_count == 1) { //如果只有一个input节点为非dead节点 NodeVector loop_exits(zone_); // Due to compaction above, the live input is at offset 0. //遍历use节点并把Phi的use节点替换为index为0的input节点 for (Node* const use : node->uses()) { if (NodeProperties::IsPhi(use)) { Replace(use, use->InputAt(0)); } elseif (use->opcode() == IrOpcode::kLoopExit && use->InputAt(1) == node) { //如果不为Phi而是loopexit并且index为1的input节点就是node //则将该use节点压入loopexits空间 // Remember the loop exits so that we can mark their loop input dead. // This has to be done after the use list iteration so that we do // not mutate the use list while it is being iterated. loop_exits.push_back(use); } elseif (use->opcode() == IrOpcode::kTerminate) { //如果为Terminate,则dead节点代替use节点 DCHECK_EQ(IrOpcode::kLoop, node->opcode()); Replace(use, dead()); } } //遍历loopexits空间,loopexits中的节点(use)将index为1的input节点替换为dead,重复visit每个节点 for (Node* loop_exit : loop_exits) { loop_exit->ReplaceInput(1, dead()); Revisit(loop_exit); } //将node用index为0的input节点代替 return Replace(node->InputAt(0)); } DCHECK_LE(2, live_input_count); DCHECK_LE(live_input_count, inputs.count()); // Trim input count for the {Merge} or {Loop} node. //如果input中肯定有dead节点 if (live_input_count < inputs.count()) { // Trim input counts for all phi uses and revisit them. //遍历该node的use节点,如果为Phi,则将node节点紧凑 for (Node* const use : node->uses()) { if (NodeProperties::IsPhi(use)) { use->ReplaceInput(live_input_count, node); TrimMergeOrPhi(use, live_input_count); Revisit(use); } } //修整node节点的live_input个数 TrimMergeOrPhi(node, live_input_count); return Changed(node); } return NoChange(); }
Reduction JSCreateLowering::Reduce(Node* node) { DisallowHeapAccess disallow_heap_access; switch (node->opcode()) { case IrOpcode::kJSCreate: return ReduceJSCreate(node); case IrOpcode::kJSCreateArguments: return ReduceJSCreateArguments(node); case IrOpcode::kJSCreateArray: return ReduceJSCreateArray(node); case IrOpcode::kJSCreateArrayIterator: return ReduceJSCreateArrayIterator(node); case IrOpcode::kJSCreateAsyncFunctionObject: return ReduceJSCreateAsyncFunctionObject(node); case IrOpcode::kJSCreateBoundFunction: return ReduceJSCreateBoundFunction(node); case IrOpcode::kJSCreateClosure: return ReduceJSCreateClosure(node); case IrOpcode::kJSCreateCollectionIterator: return ReduceJSCreateCollectionIterator(node); case IrOpcode::kJSCreateIterResultObject: return ReduceJSCreateIterResultObject(node); case IrOpcode::kJSCreateStringIterator: return ReduceJSCreateStringIterator(node); case IrOpcode::kJSCreateKeyValueArray: return ReduceJSCreateKeyValueArray(node); case IrOpcode::kJSCreatePromise: return ReduceJSCreatePromise(node); case IrOpcode::kJSCreateLiteralArray: case IrOpcode::kJSCreateLiteralObject: return ReduceJSCreateLiteralArrayOrObject(node); case IrOpcode::kJSCreateLiteralRegExp: return ReduceJSCreateLiteralRegExp(node); case IrOpcode::kJSGetTemplateObject: return ReduceJSGetTemplateObject(node); case IrOpcode::kJSCreateEmptyLiteralArray: return ReduceJSCreateEmptyLiteralArray(node); case IrOpcode::kJSCreateEmptyLiteralObject: return ReduceJSCreateEmptyLiteralObject(node); case IrOpcode::kJSCreateFunctionContext: return ReduceJSCreateFunctionContext(node); case IrOpcode::kJSCreateWithContext: return ReduceJSCreateWithContext(node); case IrOpcode::kJSCreateCatchContext: return ReduceJSCreateCatchContext(node); case IrOpcode::kJSCreateBlockContext: return ReduceJSCreateBlockContext(node); case IrOpcode::kJSCreateGeneratorObject: return ReduceJSCreateGeneratorObject(node); case IrOpcode::kJSCreateObject: return ReduceJSCreateObject(node); default: break; } return NoChange(); }